

A few days ago OpenAI released an artificial intelligence model called DALL-E that produces images from textual descriptions that can be expressed in natural language. The system requires a text or text+image input and outputs an image. This means, for example, that if the user writes “a butterfly-shaped chair” the model returns several versions of – you guessed it – a butterfly-shaped chair, images created on the fly by the system and not scraped from the Internet as any search engine would do. Here are some examples of the output I just described:

DALL-E (the name is a tribute to both Salvador Dalì and Pixar’s WALL-E robot) is a variant of the famous GPT-3 natural language processing model. But while GPT-3 creates texts, some of which are very convincing and often indistinguishable from those created by a human author, DALL-E, with its 12 billion parameters, specialises in graphical interpretations.
The DALL-E dataset is composed of text-image pairs, which allows the model to have a graphical representation of the individual terms. But apart from this initial training, which is a bit like showing to a child a picture and teach him how to write its name, the further combination of concepts (sometimes creating chimeras), the anthropomorphisation of objects or animals, the modification of existing images, the creation of emoji or the rendering of texts is all done by DALL-E, which can create abstractions such as a hybrid between a hedgehog and a carrot, like the images below:

The system can also receive fairly detailed instructions as input, such as “a little penguin wearing a blue hat, red gloves, green shirt and yellow trousers”, but when it needs to create associations, or when there are many parts to combine, DALL-E has a tendency to “forget” something on the way.
In the example of the penguin we can see that usually one or two of the garments are correctly coloured, but it is rare that the system draws all four with the correct colours.

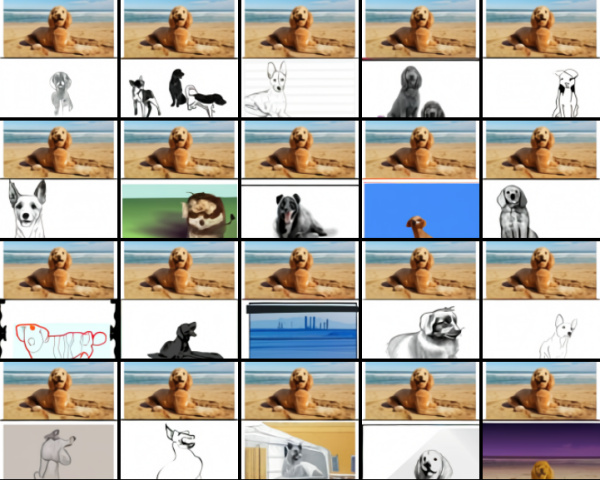
Another possibility is to input either a text string or an image. The interesting thing is that in some cases the researchers have noticed emergent qualities in the model, such as the ability known as zero-shot reasoning (in this case it should be called zero-shot visual reasoning), which allows the model to perform several tasks simply with a description and a visual aid, without the classification having been programmed beforehand.
An example of this emergent quality is the following series of pictures, where the model was asked to “draw a picture of this dog”, adding a picture of a dog on the beach:
Or this other example, where the input is basically an image of a teapot together with the instruction “the exact same teapot with ‘gpt’ written at the bottom”:

Another case where the model does not always succeed is the specific editing of images, as shown in the following example where DALL-E has been tasked to colour the dog pink. In order to do this, it must correctly identify the outlines, separate it from the background and apply the indicated changes. Many of the results that follow are far from “intelligent”:

As can be seen from the examples given so far, DALL-E often tends to create its own versions of the image, even when it had been instructed to replicate the input image precisely as it was. This is the flip side of the coin of a system trained to “fill in the blanks” not described by the input. Just as this other example demonstrates, where the system is asked to create “a loft bedroom with a white bed next to the bedside table. next to the bed is a fish tank” and adding this minimal visual prompt as aid:

The result will be a whole series of slightly different versions of the room:

As you can see, the model has made several types of fish tank, bed, bedside table, often varying the positions and adding other furniture such as a wardrobe, shelves, knick-knacks.
It is these emerging features that make DALL-E a potentially very interesting system in terms of possible uses, making it suitable for creative studios, interior designers and – why not – the fashion industry; or more in general for all activities where visual imagination is needed. Such a system would help creative people get new inspiration or to try out in a few seconds concepts that would have been long to set up graphically one by one.
Just look at what the model achieved when I asked it to create some orchid-shaped lamps:
The OpenAI researchers didn’t create DALL-E with a specific goal in mind. They had a high-performance model like the GPT-3 and they modified it to create this new system, which adds visual creativity to the “parent” model.
And just like GPT-3, it will be the market that will devise new services to exploit the model’s capabilities, but with one question that has no clear answer so far: who will own the copyright of an image generated by DALL-E following the input of the user? OpenAI has not commented on this. In the past, with its MuseNet music model, the company had declared that it did not hold the copyright of the output music, but at the same time it asked users not to use it for commercial purposes. A similar approach was adopted for the Jukebox product.
However, DALL-E opens up a number of copyright scenarios that are unlikely to be addressed by a small footnote.