
Introduction
Arhat is a cross-platform framework designed for efficient deployment of deep learning inference workflows in the cloud and at the edge. Unlike the conventional deep learning frameworks Arhat translates neural network descriptions directly into lean standalone executable code.
In developing Arhat, we pursued two principal objectives:
- providing a unified platform-agnostic approach towards deep learning deployment and
- facilitating performance evaluation of various platforms on a common basis
Arhat has been created to meet engineering challenges that are common for practical deployment of modern AI solutions.
Challenge: fragmented deep learning ecosystems
Arhat addresses engineering challenges of modern deep learning caused by high fragmentation of its hardware and software ecosystems. This fragmentation makes deployment of each deep learning model a substantial engineering project and often requires using cumbersome software stacks.
Currently, the deep learning ecosystems represent a heterogeneous collection of various software, hardware, and exchange formats, which include:
- training software frameworks that produce trained models,
- software frameworks designed specifically for inference,
- exchange formats for neural networks,
- computing hardware platforms from different vendors,
- platform-specific low level programming tools and libraries.
Training frameworks (like TensorFlow, PyTorch, or CNTK) are specialized in construction and training of deep learning models.
These frameworks do not necessarily provide the most efficient way for inference in production, therefore there are also frameworks designed specifically for inference (like OpenVINO, TensorRT, MIGraphX, or ONNX runtime), which are frequently optimized for hardware of specific vendors.
Various exchange formats (like ONNX, NNEF, TensorFlow Lite, OpenVINO IR, or UFF) are designed for porting pre-trained models between the software frameworks.
Various vendors provide computing hardware (like CPU, GPU, or specialized AI accelerators) optimized for deep learning workflows. Since deep learning is very computationally intensive, this hardware typically has various accelerator capabilities.
To utilize this hardware efficiently, there exist various platform-specific low level programming tools and libraries (like Intel oneAPI/oneDNN, NVIDIA CUDA/cuDNN, or AMD HIP/MIOpen).
All these components are evolving at a very rapid pace. Compatibility and interoperability of individual components is frequently limited. There is a clear need for a streamlined approach for navigating in this complex and constantly changing world.
Challenge: benchmarking deep learning models on various platforms
Benchmarking of deep learning performance represents a separate challenge. Teams of highly skilled software engineers at various companies are working hard on tuning of a few popular models (ResNet50 and BERT are the favorites) to squeeze the last bits of performance from their computing platforms.
However, the end users frequently want to evaluate performance of models of their own choice. Such users request methods for achieving the best performance on the chosen platforms as well as interpreting and comparing the benchmarking results. Furthermore, they typically have the limited time and budgets and might not have in their disposition the dedicated teams of deep learning experts.
The difference is like that between designing an exclusive race car and building a mass produced auto for common customers. Apparently, this task presents some interesting challenges requiring a dedicated set of tools and technologies.
Arhat: reference architecture
To address these challenges, we have developed Arhat. The main idea behind it is quite simple: what if we can generate executable code for each specific combination of a model and a target platform? Obviously, this will yield a rather compact code and can greatly simplify the deployment process.
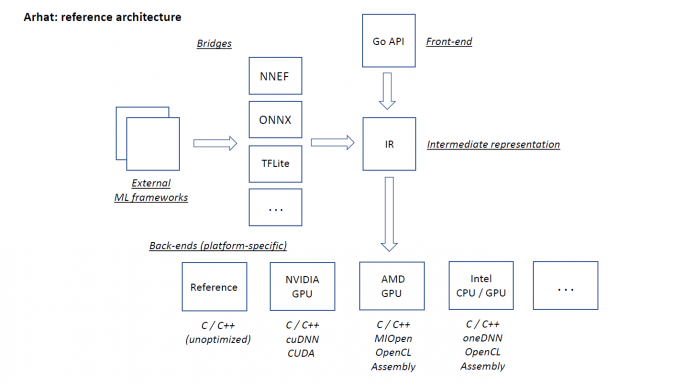
Conceptual Arhat architecture as originally designed is shown on the following figure.
The central component is Arhat engine that receives model descriptions from various sources and steers back-ends generating the platform-specific code. There are two principal ways for obtaining model descriptions:
- Arhat provides the front-end API for programmatic description of models.
- Pre-trained models can be imported from the external frameworks via bridge components supporting various exchange formats.
The interchangeable back-ends generate code for various target platforms.
This architecture is extensible and provides regular means for adding support for new model layer types, exchange formats, and target platforms.
Arhat core is implemented in pure Go programming language. Therefore, unlike most conventional platforms that use Python, we use Go also as a language for the front-end API. This API specifies models by combining tensor operators selected from an extensible and steadily growing operator catalog.
Advantages of lean software
More than 25 years passed since Prof. Niklaus Wirth has written his classical paper “A Plea for Lean Software”. Nowadays, the key concepts of this work remain as important as they were when it was published.
Specifically, the ideas of N. Wirth are fully applicable to the deep learning software with its notorious complexity. Literally following Wirth’s motto “All features, all the time”, mainstream deep learning frameworks are typically bundling support for all available neural network layer types and target hardware platforms in a single package. This inevitably leads to software systems featuring fat hierarchies of “layers of abstraction”. Of these numerous layers only a few (typically, the lower ones) implement functionality that is essential; the rest just serve as adaptors necessary to implement complex logic required for supporting all possible combinations of input models and target platforms.
The matters become even more complex when the “software stacks” combining several interacting frameworks are involved. Deployment and maintenance of such stacks present a notoriously complex problem. Of course, this problem can be addressed by modern automation tools but use of these tools itself requires significant dedicated effort thus diverting precious engineering resources from solving the original problem.
Automated code generation comes to rescue in these cases as it allows creation of very lean software code for each specific combination of input model and target platform. The complex software logic and respective numerous layers of abstractions do not fully disappear; however, they are encapsulated within a framework that implements the off-line code generation. The generated deployable code contains only functionality essential for the given application with the minimum dependencies on the external software components.
Minimum external dependencies
Although we made every effort to keep at minimum dependencies on external software components, there are several third-party toolkits and libraries that are essential for the efficient use of Arhat. These components form two main groups: (1) vendor-specific libraries of deep learning primitives and (2) conversion tools for external model formats.
Vendor-specific libraries provide implementation of common deep learning primitives (like convolutions, pooling, or fully connected layers) that are highly optimized for the specific hardware platforms. These libraries are created and maintained by highly skilled teams of engineers deeply familiar with their hardware and use of these libraries is essential for efficient native deployment of deep learning applications.
Conversion tools for external formats are required for importing models trained with various external frameworks. These tools typically implement routine but cumbersome model transformations and a wide range of them is available as open source software. Therefore, it would make little sense to reimplement their functionality in Arhat; it is sufficient just to choose one most versatile and extensible of these tools and implement the respective interface for Arhat.
To illustrate this approach, following is a brief description of just two among the chosen external software components: (1) Intel OpenVINO Model Optimizer and (2) NVIDIA TensorRT inference library. These components belong to different larger packages of different vendors but nevertheless they work perfectly well together with Arhat.
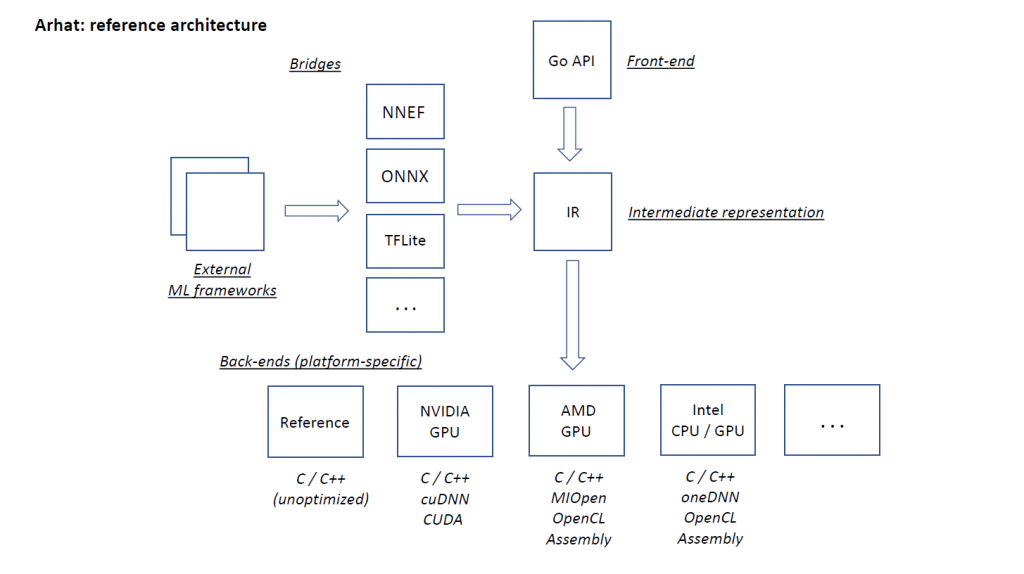
Intel OpenVINO toolkit allows developers to deploy pre-trained models on various Intel hardware platforms. It includes the Model Optimizer tool that converts pre-trained models from various popular formats to the uniform Intermediate Representation (IR).
We leverage OpenVINO Model Optimizer for supporting various model representation formats in Arhat. For this purpose, we have designed the OpenVINO IR bridge that can import models produced by the OpenVINO Model Optimizer. This immediately enables Arhat to handle all model formats supported by OpenVINO.
The respective workflow is shown on the following figure.
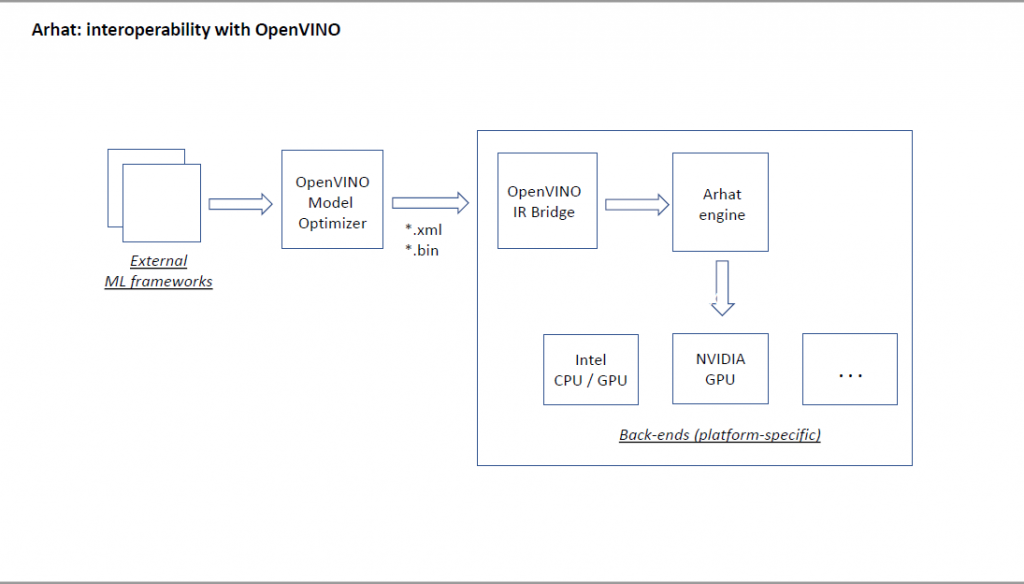
TensorRT is a tool that provides the best inference performance on NVIDIA GPU platforms. To leverage the power of TensorRT we have implemented a specialized back-end generating code that calls TensorRT C++ inference library.
The respective workflow is shown on the following figure.
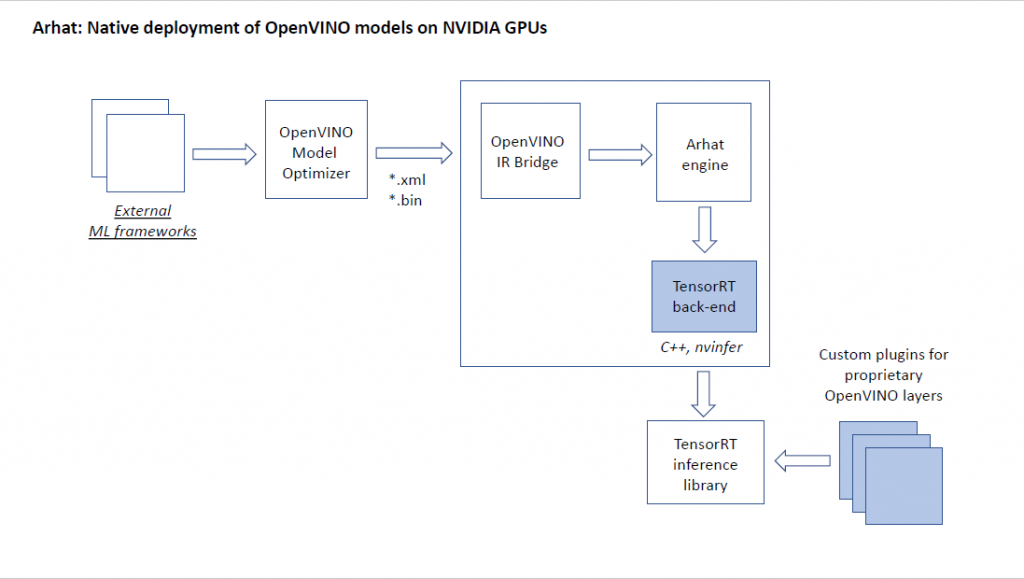
There are several proprietary Arhat layer types that are not directly supported by TensorRT. We have implemented them in CUDA as custom TensorRT plugins.
Integration of Arhat with such external components required certain effort that yielded valuable results. Now Arhat allows to transcend the “natural” boundaries of platform-specific software and to extend outreach of its components by adding functionality that is not originally available. For example, we used Arhat to natively deploy models from Intel Model Zoo on NVIDIA GPU platforms. “You can get much farther with vendor tools and Arhat than with vendor tools alone”.
Case study: porting Detectron2 models to Arhat
Following the successful series of experiments with deployment of various object detection models from OpenVINO Model Zoo on various targets we have chosen a more challenging task. This time we decided to use Arhat for automated generation of inference code for models of Detectron2, a popular open source PyTorch deep learning library.
Detectron2 provides a few built-in deployment options but only one appears suitable for our task. We have used Caffe2 tracing method to generate ONNX model representation. This is not a standard ONNX as it involves a handful of custom operations available only in Caffe2. We routinely use OpenVINO Model Optimizer for importing ONNX models in Arhat; however, this time the regular software version would not work because of these non-standard operations. Fortunately, the Model Optimizer provides a convenient extension mechanism, and it was not too difficult to implement the respective plugins.
The next step included implementation of custom Caffe2 operations in Arhat framework. We did this using the original Caffe2 C++ code as blueprints. With all these enhancements, we successfully generated inference code for a selected Faster R-CNN model and tested it on various NVIDIA GPUs. Debugging was a bit tricky but finally we can convert Detectron2 models to very lean C++ code that interacts directly with platform libraries and does not require any external framework like PyTorch or Caffe2.
We have deployed and benchmarked both the original PyTorch and the Arhat implementations of the model on the NVIDIA RTX 3080 GPU machine at Genesis Cloud. The Arhat version runs inference more than ten times faster compared the original PyTorch implementation.
Conclusion
Arhat performs automated generation of software code specific for the selected deep learning model and target platform. This results in a very lean application code with minimum external dependencies. Deployment and maintenance of such applications requires much lesser effort compared to the mainstream approach.
When used for deployment of inference workflows, Arhat can combine heterogeneous tools of different vendors (like Intel OpenVINO and NVIDIA TensorRT) that are most suitable for handling the given task. This opens a way for achieving the best computational performance on any hardware.
Arhat can be used for the streamlined on-demand benchmarking of models on various platforms. Using Arhat for performance evaluation eliminates overhead that might be caused by external deep learning frameworks because code generated by Arhat directly interacts with the optimized platform-specific deep learning libraries.
The post Arhat deep learning framework: a novel approach to meeting challenges of modern AI world appeared first on Artificial Intelligence news.